Modular Monolith Data Isolation

I'm a seasoned software architect and Microsoft MVP for Developer Technologies. I talk about all things .NET and post new YouTube videos every week.
Modular monoliths are an architectural approach that's becoming very popular. They combine the benefits of modularity and monolithic design.
Modular monoliths try to solve the shortcomings of monolithic and microservice architectures.
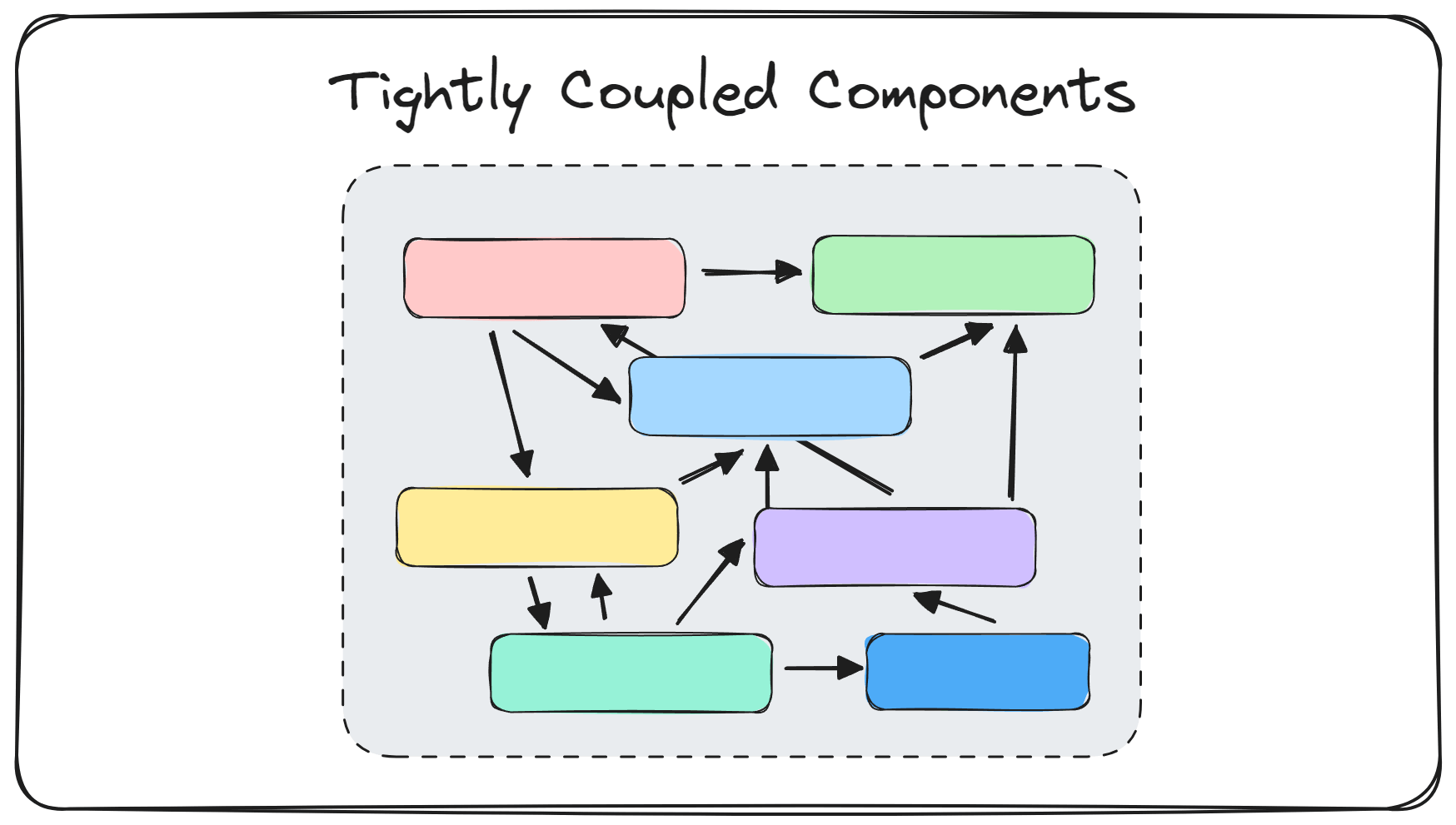
One problem I often see with monolithic architectures is tight coupling between components.
This leads to dependencies between different parts of the system.
Modular monoliths enforce better architectural practices with well-defined module boundaries and communication patterns.
But one aspect you can't overlook is data isolation between modules.
Data isolation ensures that modules are independent and loosely coupled.
Today, I will show you four data isolation approaches for modular monoliths:
Separate table
Separate schema
Separate database
Different persistence
Why Is Data Isolation Important?
Let's first understand why data isolation is important in a modular monolith architecture.
A modular monolith has strict rules for data integrity:
Each module can only access its own tables
No sharing of tables or objects between modules
Joins are only allowed between tables of the same module
Modules inside a modular monolith should be self-contained. Each module handles its own data. Other modules can access that data using the module's public API.
What are the benefits of this design?
Keeping modules isolated from each other promotes modularity and loose coupling. It makes it easier to introduce new changes to the system. There are fewer unintended side effects when components are loosely coupled.
If you are using a relational database, you can still maintain referential integrity. Removing the foreign keys when extracting tables is not a problem.
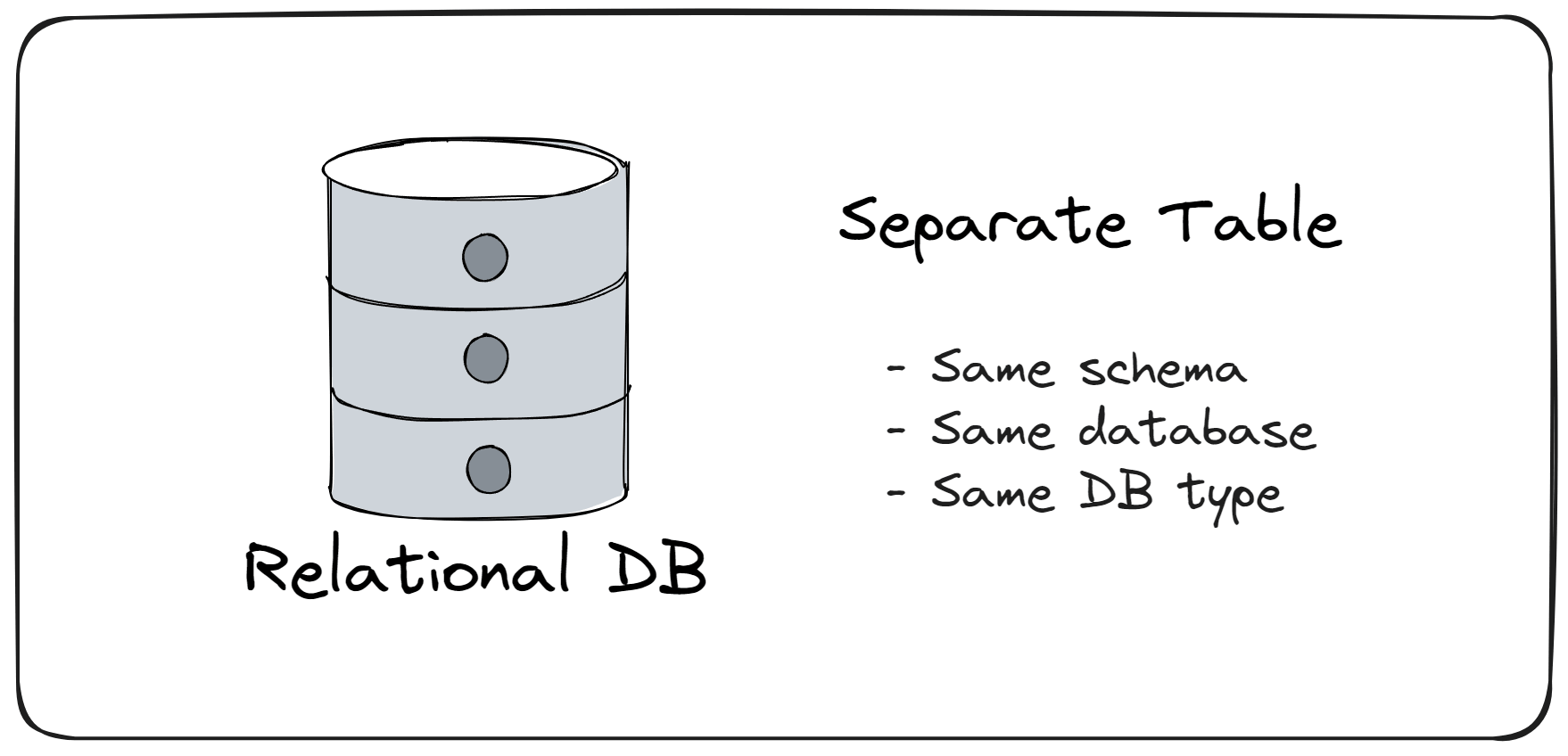
Level 1 - Separate Table
The simplest solution is to have no isolation at the database level. Tables for all modules live inside one database. It's not easy to determine which tables belong to which module.
I'm only mentioning this approach for the sake of completeness.
But this approach works fine up to a particular application size.
However, the more tables you have, the harder it becomes to keep them isolated between modules.
You can improve this by adding logical isolation between tables.
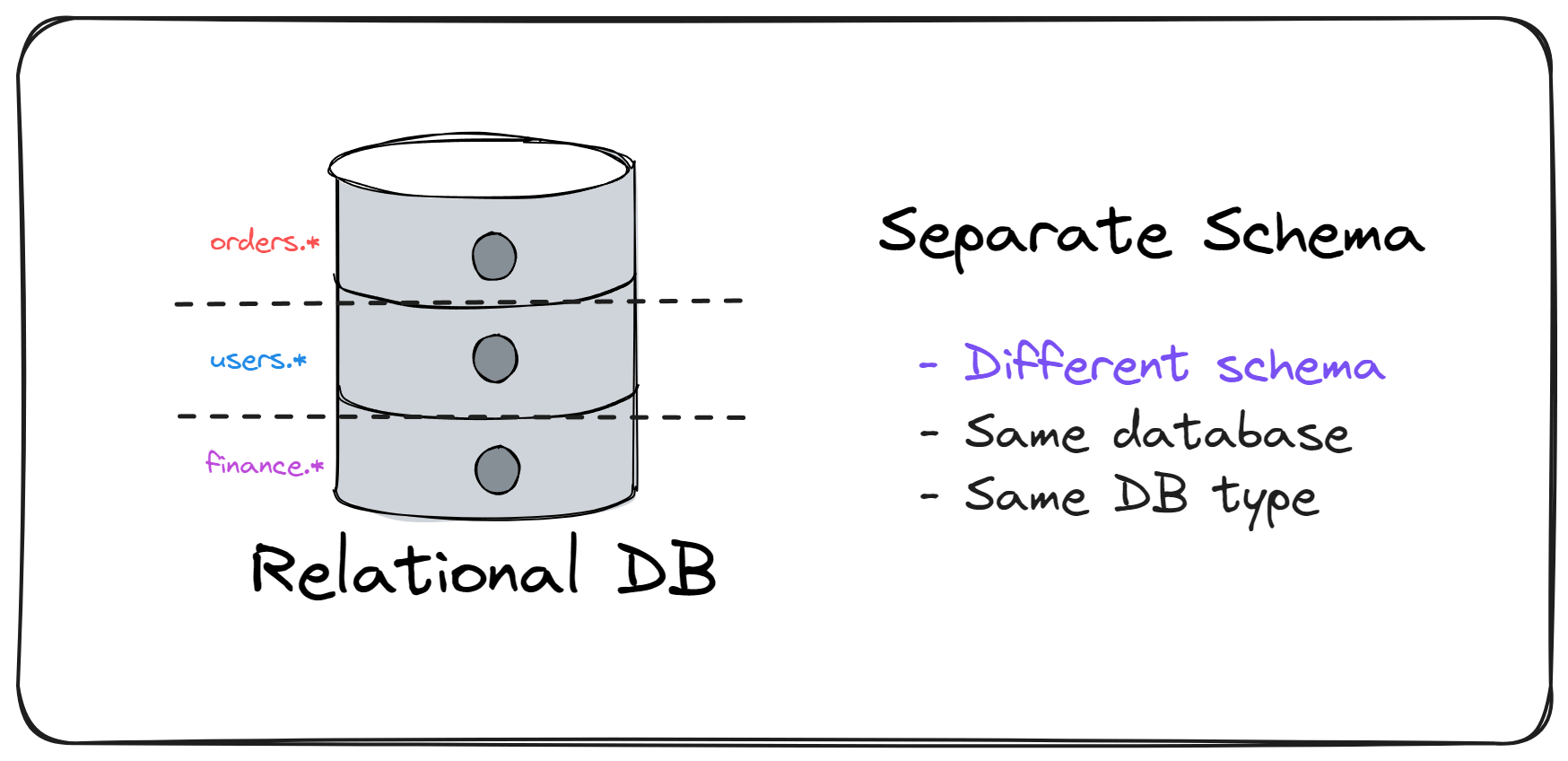
Level 2 - Separate Schema
Grouping related tables in the database is a way to introduce logical isolation. You can implement this using database schemas. Each module has a unique schema containing the module's tables.
Now, it becomes easy to distinguish which module contains which tables.
An easy way to implement this is using multiple EF Core database contexts.
You can also introduce rules to prevent querying data from other modules. For example, you could implement this using architecture tests.
I always start with logical data isolation when building a modular monolith.
But what if this isn't enough?
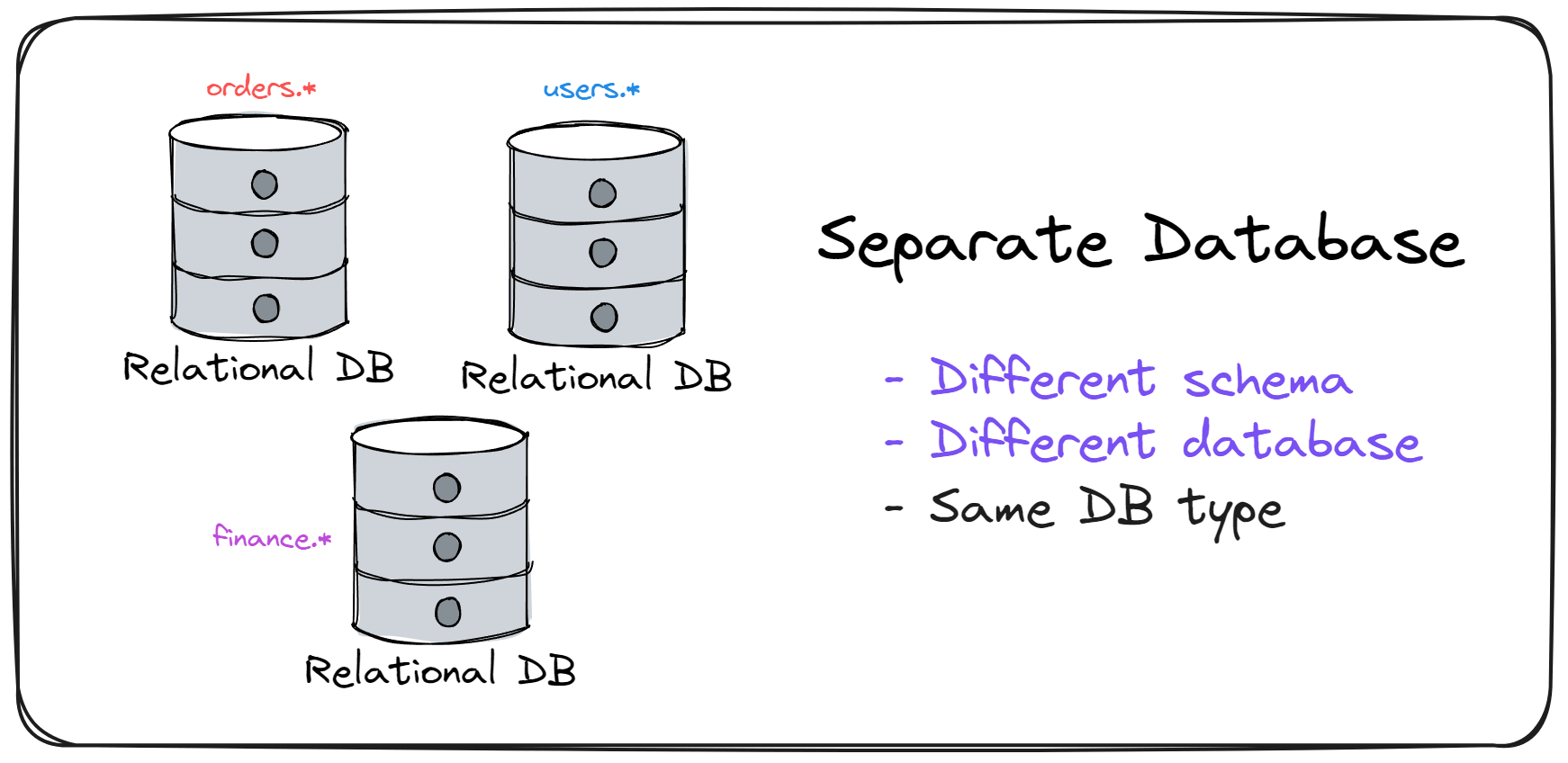
Level 3 - Separate Database
The next data isolation level is moving each module's data into separate databases. This approach has more constraints than data isolation using schemas.
This is the way to go if you need strict data isolation rules between modules. But, the downside is more operational complexity. You have to manage infrastructure for multiple databases.
However, this is an excellent step toward extracting modules.
First, you move the tables of the module you want to extract into a separate database. This also forces you to solve any database coupling problems between your modules. You're ready to extract the module once you move the tables into a separate database.
Can we take the module data isolation further?
Level 4 - Different Persistence
Who says you have to use the same database type for all modules?
I work with relational (SQL) databases most of the time. Relational databases are amazing and solve a wide range of problems. But sometimes, a document or graph database is a much better solution.
The idea here is similar: you're doing data isolation using separate databases.
However, you can introduce a different database type to solve specific problems. For example, you can use a relational database for one module. And a graph or column-store database for another module. You also have to maintain different persistence models in your application.
This could be a worthwhile tradeoff for your use case. But it takes careful planning.

Summary
Modular monoliths are excellent if you don't need microservices right away. You develop your application as a monolith with distinct boundaries inside the system. You still have the flexibility to extract modules and move to microservices. But you have faster development speed with a modular monolith.
Modules have to comply with a few rules. They can only access their own tables. They can't share tables with other modules. And they can't directly query tables of other modules. These rules help to enforce data isolation between modules.
But you still have to implement data isolation at the database level.
There are four options you can choose from:
Separate table
Separate schema
Separate database
Different persistence
I always go for logical isolation using schemas. It's easy to implement and helps me understand my boundaries better. Depending on the requirements, I can introduce separate databases later.
Hope this was helpful.
See you next week.
P.S. Whenever you’re ready, there are 2 ways I can help you:
Pragmatic Clean Architecture: This comprehensive course will teach you the system I use to ship production-ready applications using Clean Architecture. Learn how to apply the best practices of modern software architecture. Join 1,600+ students here.
Patreon Community: Think like a senior software engineer with access to the source code I use in my YouTube videos and exclusive discounts for my courses. Join 940+ engineers here.




